
很多企业在AI落地遇到的问题并不是“有没有模型”,而是 GPU 不够用、无法支撑核心业务接入AI后的吞吐量。
一边是整卡分配、峰值采购、人工协调;另一边是轻量推理、实验任务、多租户服务同时增长。结果就是卡买了不少,业务还是觉得不够用,平台团队也越来越重。 同思引擎(Tensor Engine)解决的不是单纯“切卡”,而是把 GPU 从固定硬件改成可虚拟化、可池化、可调度、可统一运营的算力底座。

为什么 GPU 总是不够用
多数团队会同时遇到四个问题:
- 整卡交付太粗。 一个只要几 GiB 显存的小模型,也经常占住整张卡。
- 资源分散。 GPU 分散在不同节点、不同集群、不同项目里,闲置和排队同时存在。
- 高峰靠加卡。 为了扛住峰值体验,只能按最坏情况采购,日常大量时间都在为空转买单。
- 平台越来越重。 调度、配额、监控、计量、租户隔离都要补,系统越堆越复杂。
问题不在“怎么把一张卡分给更多人”,而在于怎么把整池 GPU 做成可按业务供给的资源层。
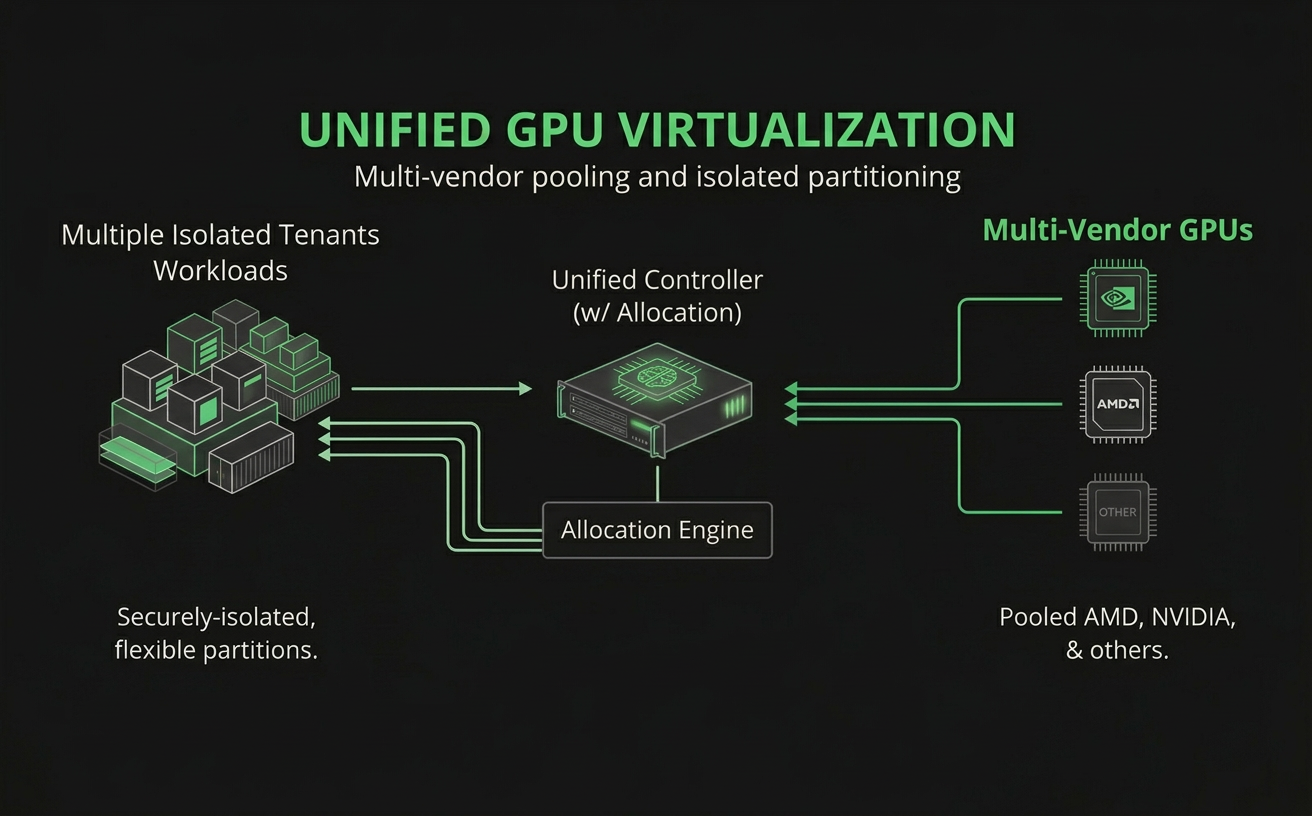
同思引擎的关键,不只是切分,而是异构虚拟化和双栈交付
同思引擎适合企业场景,不是因为它能共享 GPU,而是因为它把几个关键能力放在了一起:
- 异构虚拟化。 不只盯着单一型号或单一厂商 GPU,而是面向企业真实环境做统一纳管。
- 容器和 VM 双栈。 既支持 Kubernetes 集群中的 AI 工作负载,也支持宿主机/虚拟机场景下的 GPU 交付。
- 强隔离与标准化供给。 资源不是“谁先抢到谁用”,而是按显存、算力、QoS、隔离等级统一交付。
- 整池视角调度。 优化目标不是某一张卡,而是整池利用率、业务弹性和交付效率。
对于已经有容器平台的团队,同思引擎可以直接接到现有 K8s 工作负载里;对于私有云和虚拟机环境,同样可以通过 Host/Guest VM 模式交付 GPU 能力,不必把所有业务先改造成容器。
AI PaaS 怎么接入:从注解开始,把切分、调度和纳管收进一套规则
很多团队不缺调度器,缺的是业务侧能不能用同一套方式申请 GPU。 同思引擎在 K8s 场景里,把这件事收敛成了标准化 annotation。工作负载只需要声明显存、算力、QoS 和注入容器,平台就可以做统一切分、调度和运维。
一个简化后的 annotation 用法大致如下:
template:
metadata:
annotations:
tensor-fusion.ai/inject-container: pytorch
tensor-fusion.ai/tflops-request: "10"
tensor-fusion.ai/tflops-limit: "20"
tensor-fusion.ai/vram-request: "4Gi"
tensor-fusion.ai/vram-limit: "4Gi"
tensor-fusion.ai/qos: "medium"
tensor-fusion.ai/workload-profile: "default-profile"这类配置的意义很直接:
- 业务团队按 workload 申请 GPU,不再按整卡抢资源
- 平台团队可以统一做配额、调度、灰度迁移和运维
- 同一套规则能覆盖小模型推理、实验任务和更长期运行的服务
如果再往上走到 AI PaaS 层,统一切分、统一调度、统一纳管和统一运维就不再是四套系统,而是一套平台能力。
为什么安徽融合智算把同思引擎做成底座能力
安徽融合智算不是只做一个“GPU 功能点”,而是围绕 算力池化、模型推理、企业智能体 做完整产品栈。 同思引擎负责把底层 GPU 做成可运营资源层;往上才能更稳定地承接模型推理平台、AI PaaS 和企业智能体应用。
对客户来说,这种组合的价值在于:做项目时不用把“底层算力治理”和“上层业务交付”拆成两次采购、两套团队、两轮集成。

成功案例
1. 某全球协作平台:多模型推理成本优化 58%–65%
一类典型客户,是全球多区域、多业务线、多模型并行运行的平台型公司。 这类场景的问题不是“单个模型算力不够”,而是 100+ 模型、十余个 Region、20+ 业务线叠加后,整卡分配会把碎片和冗余同步放大。
在该项目中,团队在保障业务高峰期仍保留 40% GPU 冗余 的前提下,实现了 58%–65% 的推理成本优化。 这里最关键的,不是把某一张卡切得更细,而是让多模型推理开始共享同一池算力,并且支持渐进迁移和灰度切换。
2. 云轴科技 ZStack:私有云 VM 场景下做算力切分和强隔离
另一类典型场景,是以私有云和虚拟机为主的企业环境。 这类客户往往更关心三件事:业务仍跑在 VM 里、隔离必须足够强、又不想继续用 GPU 直通把资源锁死。
在 TensorFusion 的 VM 模式里,worker 运行在宿主机,client 运行在 VM 内,虚拟机可以通过网络或共享内存使用宿主机 GPU 资源,不必先把业务整体迁到容器。文档里已经给出了 Host/Guest VM 安装方式,也明确支持 Windows/Linux VM vGPU 交付路径。 这意味着像云轴科技 ZStack 这样的私有云场景,可以把 GPU 做成更细粒度、更强隔离、更容易复制交付的资源能力,而不是继续“一台虚机绑定一张卡”。
对于私有云团队来说,这类方案最有价值的地方不是炫技,而是:
- VM 业务不用大改架构
- GPU 不必长期直通给单个虚机
- 资源边界、隔离方式和交付规则更清晰
- 私有云里也能做细粒度算力供给
3. 十方融海:AI 实训环境可用率做到 99.9%
十方融海的 AI 实训场景更能说明“为什么企业买了 GPU,还是总觉得不够用”。 实训业务的难点不是卡本身,而是每位学员都要有可用环境,但平台又不可能长期按“一人一卡”建设。
在这个场景里,同思引擎解决的是三件事:
- 多位学员共享同一批 GPU,而不是一人独占一张卡
- 高峰上课时段仍然保证环境稳定可用
- 平台能根据课程高峰和作业波峰统一调度有限算力
最后带来的结果是:
- 实训环境可用率提升到 99.9%
- 显卡有效利用率从不足 25% 提升到 60% 以上
- 单学员算力成本降低超 80%
- 新实训环境搭建时间缩短约 45%

更多案例详情,请关注公众号后续文章推送。
什么情况下,该认真评估同思引擎
如果你的团队已经出现下面这些信号,就值得认真评估:
- GPU 买了不少,但利用率始终不高
- 同时跑的模型越来越多,资源越来越碎
- 容器和 VM 场景并存,交付方式很难统一
- 平台团队开始频繁处理排队、抢卡、手工协调
- 想做统一 AI PaaS 或算力平台,但不想继续堆拼装组件
企业之所以总觉得 GPU 不够用,通常是因为资源组织方式还停留在整卡交付。 同思引擎把 GPU 变成统一资源池、统一调度规则和统一交付方式,让算力能够按业务供给。