
买了 8 卡、显存接近 1TB 的一体机,模型装得下,演示跑得顺。但一到真实业务流量,系统就开始排队——知识问答多起来慢,再叠一个审查辅助就更慢。机器看着不小,用户体感却还是"卡"。
吞吐上不去,原因几乎从不是"模型装不进去"。 真正拦住产能的,是另外四笔账:算、存、传、排。把这四笔账理顺,才能让机器真正跑满。
吞吐是什么
很多人把"吞吐"理解成"回答快不快",其实不完全对。
吞吐更像是一台机器在单位时间里,能稳定接住多少请求、吐出多少 token(词元,也就是模型每次输出的最小单位)。
单次问答快,只能说明它会跑。高并发时还能稳住,才说明它真的有产能。这就像一家餐厅:空店时出一份菜很快,不代表晚高峰也能稳稳出餐。企业真正关心的,不是"样板间里最快能跑多快",而是业务高峰时会不会堵、会不会排队、会不会抖动。
第一笔账:算力
推理大致分两个阶段:
- 预填充:把问题、上下文、知识库片段全部读完、并行处理。
- 逐词生成:一个字一个字往外输出。
这两段对硬件的要求截然不同。前一段更像"大批量并行计算",吃的是算力;后一段更像"反复从显存里搬运数据",吃的是内存带宽。
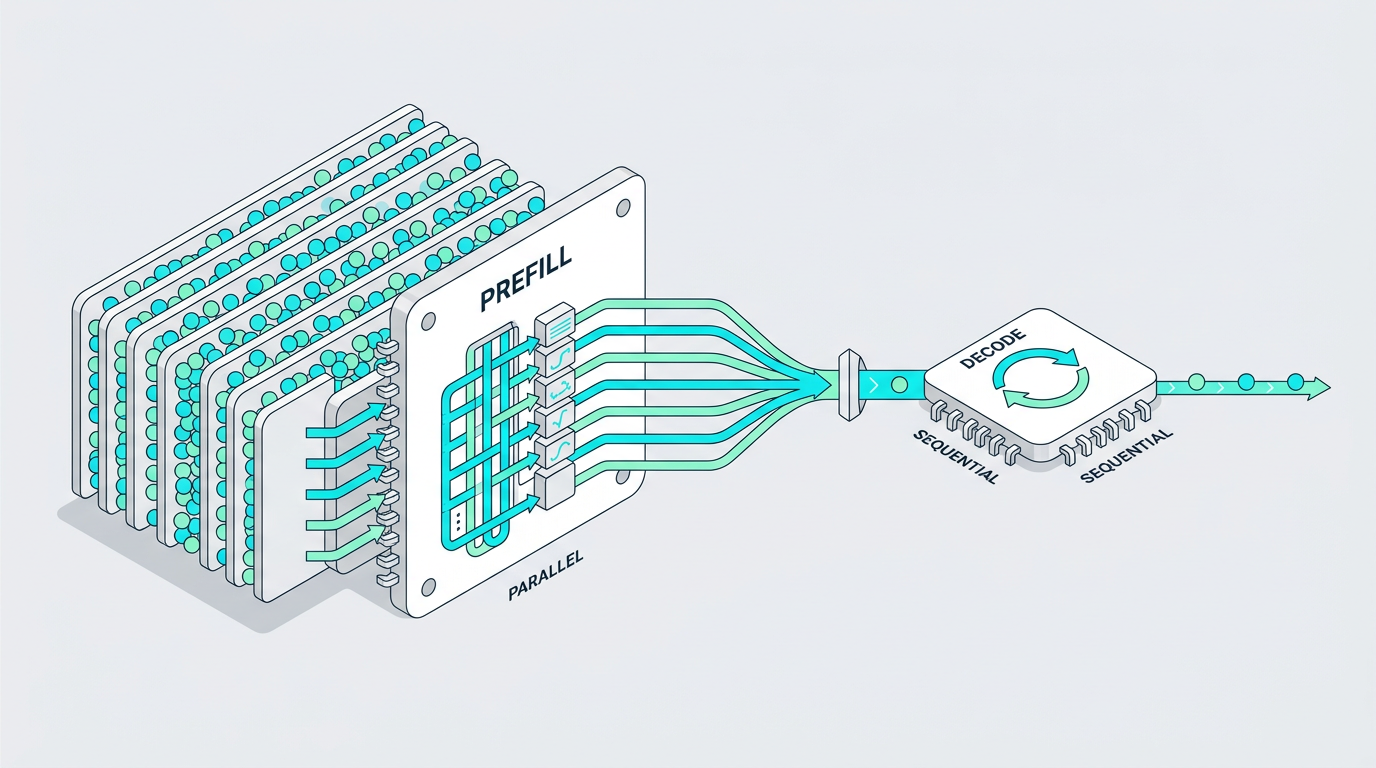
很多一体机项目里,真正拖后腿的是后一段——生成阶段没跑顺,GPU 利用率上不去。
能跑通一个 32B 模型,和能高吞吐地服务一群真实用户,中间隔着很长一段工程距离。
第二笔账:显存
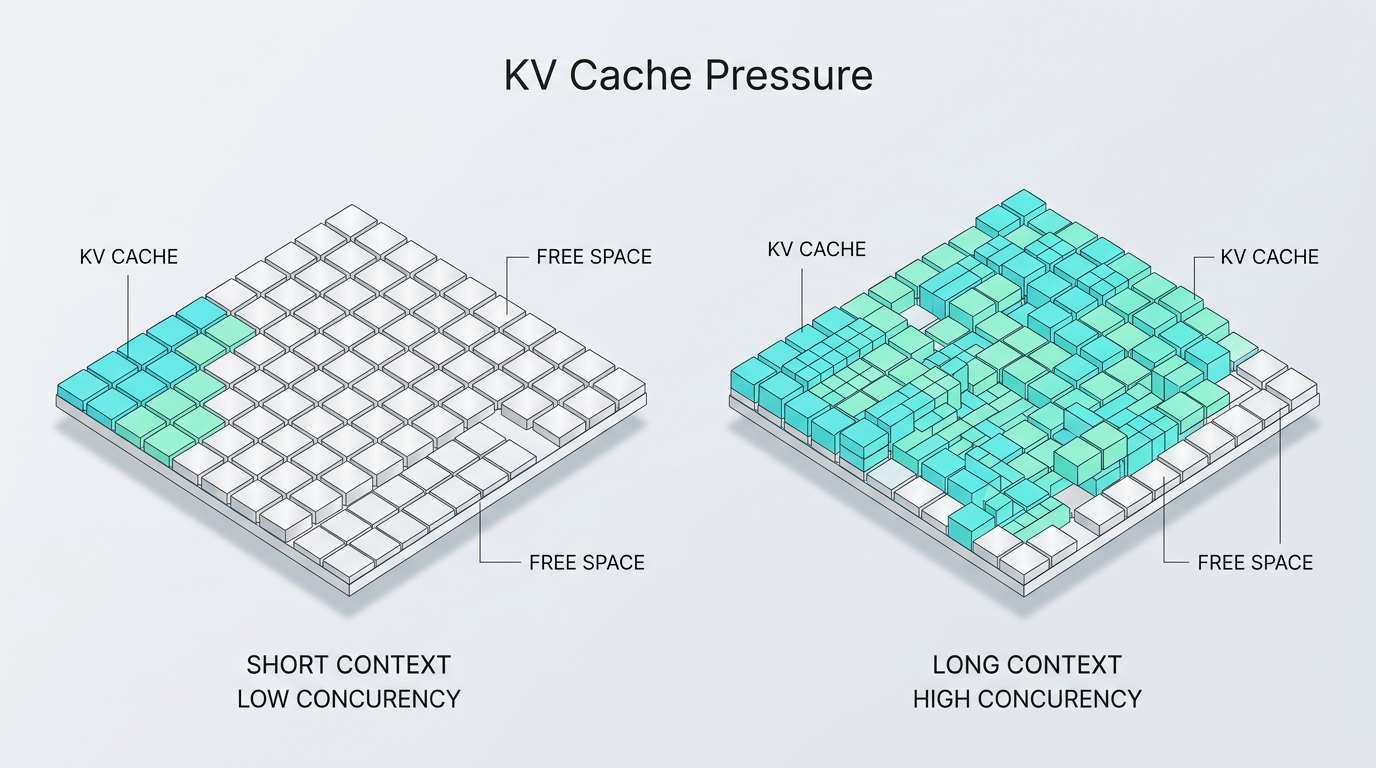
模型装进显存了,为什么并发还是起不来?
因为显存不只用来放模型,还要放模型的"短期记忆"。这部分业内叫 KV Cache(键值缓存)——可以理解成:模型在对话时,为了记住前面说过什么,会把一部分中间结果暂存在显存里,方便后续继续生成。
问题在于:
- 用户上下文越长,这块"记忆"越大。
- 同时在线的人越多,这块"记忆"越多。
- 记忆一多,显存就被挤满,并发空间随之收窄。
这也是为什么很多系统在短问答时还行,一上长文档问答、RAG(检索增强生成,即先从知识库搜索资料再让模型回答)、多轮对话,吞吐就明显掉下来。不是模型变笨了,而是显存开始被上下文和缓存吃掉了。
传统方案里显存碎片和预留浪费可能达到 60% 到 80%。vLLM 等推理框架通过 PagedAttention(分页注意力,类似操作系统管理内存的方式,按需分配,不预留大块)把浪费压到很低的水平,让系统能塞进更多并发请求。
一体机的显存参数,不是看"仓库面积",而是要看营业中的**"周转空间"**。仓库再大,如果过道被临时堆满,车一样进不来。
第三笔账:传输
这是采购阶段最容易被低估的一笔账。
很多人以为:单卡性能不错,8 张卡放在一起,吞吐大致就是 8 倍附近。现实里经常不是这样。
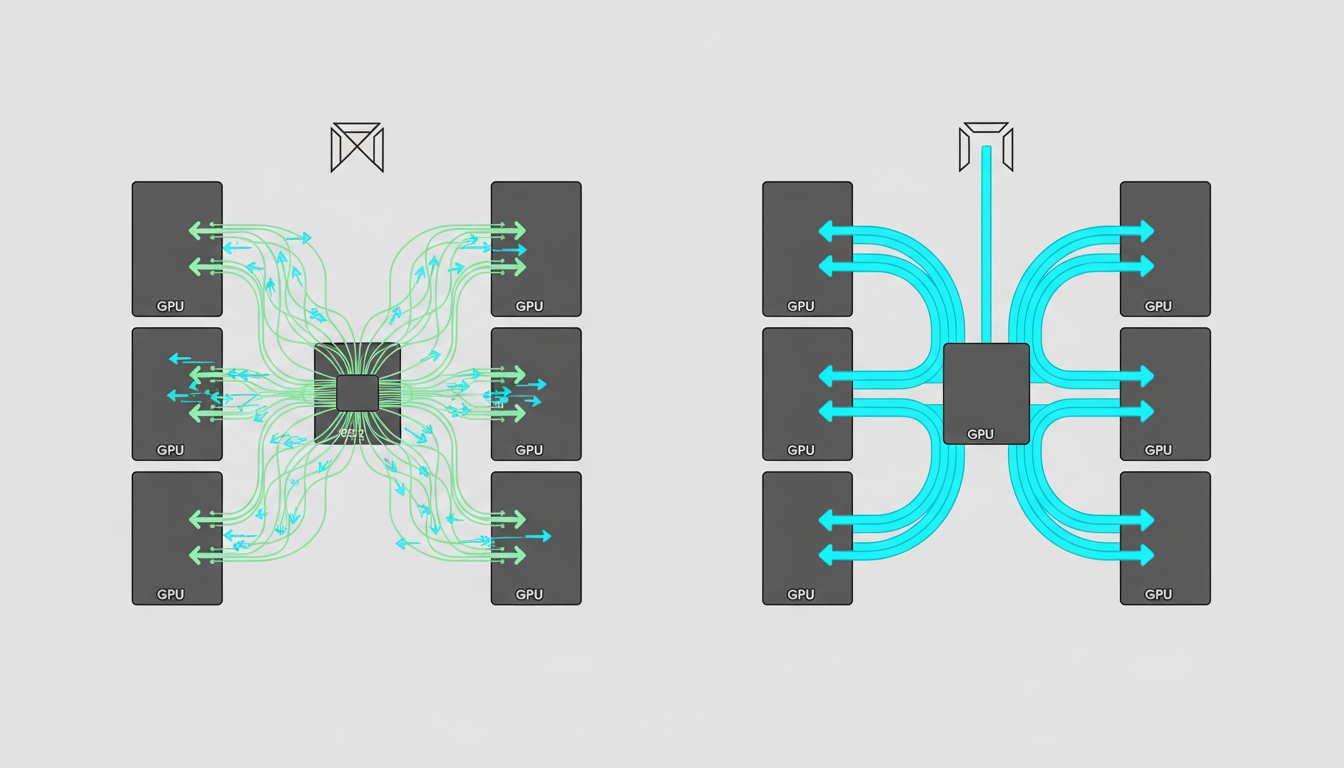
多卡推理不是"8 台机器各做各的",而是8 张卡要频繁交换数据、彼此等待。只要卡和卡之间传得不够快,整体速度就会被拖住。
我们做过一个测试:8 张 RTX 5090、PCIe 5.0 互联,这台机器规格不弱。结果很说明问题——TP=8(8 卡张量并行)配置下,每层 forward 有多次 NCCL 集体通信(NCCL 是英伟达的多卡通信库),62 层加起来共 100 多次。通信延迟占了每个词元出字耗时的 60% 以上。计算侧的各种小优化,收益直接被卡间同步开销吃掉。
翻译成人话:路不够宽,多加几辆车,不一定更快。
PCIe 5.0 的卡间有效带宽约 64 GB/s,而 NVLink 4 能达到 900 GB/s,差了 14 倍。同样是 8 张卡,互联方式不同,结果可能天壤之别。
所以看一体机,不能只看"有几张卡、多少显存",还要看:
- 卡和卡之间怎么连(NVLink 还是 PCIe)
- 推理框架对这套互联的适配程度
第四笔账:排队
企业真实流量,不是实验室里的标准题。有的请求很短,有的特别长;有的用户只问一句,有的会连续追问;有的请求刚进来还在"读题",有的已经在持续出字。
如果系统不会调度,这些请求混在一起就很容易互相拖慢。
现在主流推理框架越来越强调两件事:
- 连续批处理:新请求不必等老请求全部跑完再上车,随到随加入,提高 GPU 利用率。
- 更聪明的调度策略:在"先服务老请求"还是"尽快接新请求"之间做动态平衡。
调度器在每一步决定"哪些请求现在能上、哪些先等"。这一步做不好,就算模型和硬件没问题,吞吐也会掉下来。
很多一体机项目的真正问题是:线上服务还停留在单机跑基准测试的思路里。
如果是 MoE,还有一笔"分诊账"
MoE(混合专家模型)可以理解成:模型里不是所有能力同时工作,而是来一个问题,先做一次"分诊",再送到少数几个更合适的"专家"那里处理。Qwen3.5、Kimi-2.5、GLM-5 这些模型都是这个思路——总参数很大,但每个 token 真正激活的只是其中一部分。
好处是省算力,代价是请求不会平均落到所有专家身上。
一个典型场景:企业把 MoE 模型接进统一知识助手后,白天 9 点到 11 点,用户问题大量集中在制度查询、报销流程、合规问答。结果不是所有专家一起忙,而是少数几个"热门专家"持续排队,整体首字时间开始抖动。
后来真正起作用的,不是换一台更大的机器,而是重新整理专家分布,给热点专家做分流,吞吐才稳定下来。
使用 MoE 模型,一定要多问:
- 每次真正激活多少参数
- 热门专家会不会拥堵
- 路由和负载有没有做平衡

选型和验收,按这个顺序看
1. 先分清目标:能跑,还是能扛
内部验证、固定人数、固定上下文长度,一体机通常没问题。
如果是多部门共享、线上流量波动、长上下文常态化,你要看的就不再是"模型装不装得下",而是高峰期能不能稳定输出。
2. 别只看单次速度,要看三类指标
- 首字时间:用户发出请求到第一个字出来的延迟
- 持续出字速度:每秒生成多少词元
- 并发上来后的排队和抖动:高峰期系统是否稳定
只看单次问答,很容易误判。
3. 先把显存理顺,再谈并发
不要默认所有业务都开超长上下文;用成熟推理框架管理 KV Cache;让长输入分块处理,别一次把车道堵死。
4. 把互联当核心配置,而不是附件
同样是 8 卡,互联方式不同,结果可能差很多。有些机器的问题,不是卡不够强,而是卡和卡之间"说话太慢"。
5. MoE 单独验,不要按 Dense 模型思路套
Dense 模型(所有参数都参与计算的传统大模型)看的是统一流水线。MoE 还要多看一层"分诊和分流"。参数越大,这个问题有时反而越隐蔽。
什么时候不要迷信一体机
如果你的场景同时满足下面三条,就不要把"再买一台更大的单机"当成主要答案了:
- 服务对象很多,存在明显的流量峰谷
- 长上下文是常态,不是偶发
- 你关心的是长期稳定 SLA(服务质量承诺),而不是偶尔跑演示
这时候,问题往往已经不是"单机够不够大",而是推理服务要不要拆开做、调度要不要平台化、不同阶段要不要分开扩缩容。预填充和逐词生成天生是两种不同负载,强行绑在一起,不总是最优解。
回到最初的问题
为什么大模型一体机吞吐上不去?
因为企业买到的,很多时候只是一台能把模型装进去的机器;但真正决定体验的,是有没有把算力利用、显存占用、卡间传输和在线调度这四笔账理顺。
Dense 模型,重点是打通"算、存、传、排"这四层流水线。MoE 还要多问一句:分诊是不是均衡,热门专家会不会堵。
企业买的不是"更大的参数容量",而是让 token 稳定输出的能力。
参考链接
https://developer.nvidia.com/blog/deploying-disaggregated-llm-inference-workloads-on-kubernetes/ https://vllm.ai/blog/vllm https://arxiv.org/abs/2309.06180 https://developer.nvidia.com/blog/streamlining-ai-inference-performance-and-deployment-with-nvidia-tensorrt-llm-chunked-prefill/ https://nvidia.github.io/TensorRT-LLM/torch/scheduler.html https://nvidia.github.io/TensorRT-LLM/performance/performance-tuning-guide/tuning-max-batch-size-and-max-num-tokens.html https://arxiv.org/abs/2412.19437