
最近看了一个客户的销售助手智能体的压测记录,心里有点复杂——一条客户咨询工单从进来到产生一条合格回复,中间居然来回跑了 8 个不同的模型,参数量从 0.5B 一路跨到 70B+。原本配给这套系统的是 4 张 A100,第一版上线就顶不住。
不是卡不够,是卡不够用的方式不对。做企业智能体做到一定阶段就会发现:上面那套系统能不能跑起来,很大程度上不是看模型本身,而是看底下这层 GPU 怎么摆。

先把一条请求,铺平了摆出来
不然后面说的每件事都没有落点。一封客户咨询工单进来,完整走下来是:
- 入口安全,0.5B–1B:查有没有提示词注入、敏感信息、恶意指令。每条请求都要过,延迟要压在几十毫秒。
- 意图识别,1B–3B:这是咨询、催单、投诉,还是合同问题,决定往下走哪条分支。
- 附件解析,2B–4B 视觉语言模型:客户发了合同 PDF 或订单截图就走这一步,做 OCR 和结构化。流量很不均匀,白天一堆,晚上几乎没有。
- 向量化,300M–2B 嵌入模型:把客户问题和历史沟通转成向量送去检索。
- 重排序,2B–7B:检索拉回一批候选后再挑一遍,选最相关的几条。
- 深度推理,70B+ 或 MoE(混合专家模型,总参数很大但每次只激活其中少数几个专家):比对合同条款、判断回款风险、给多步建议。慢、贵,只有大约 20% 的请求走到这一步。
- 回复生成,8B–30B:把答案按公司话术写成一封能发出去的邮件。几乎每条请求都要跑。
- 风险复核,1B–3B:发出前再过一道,有没有泄密,有没有乱承诺。
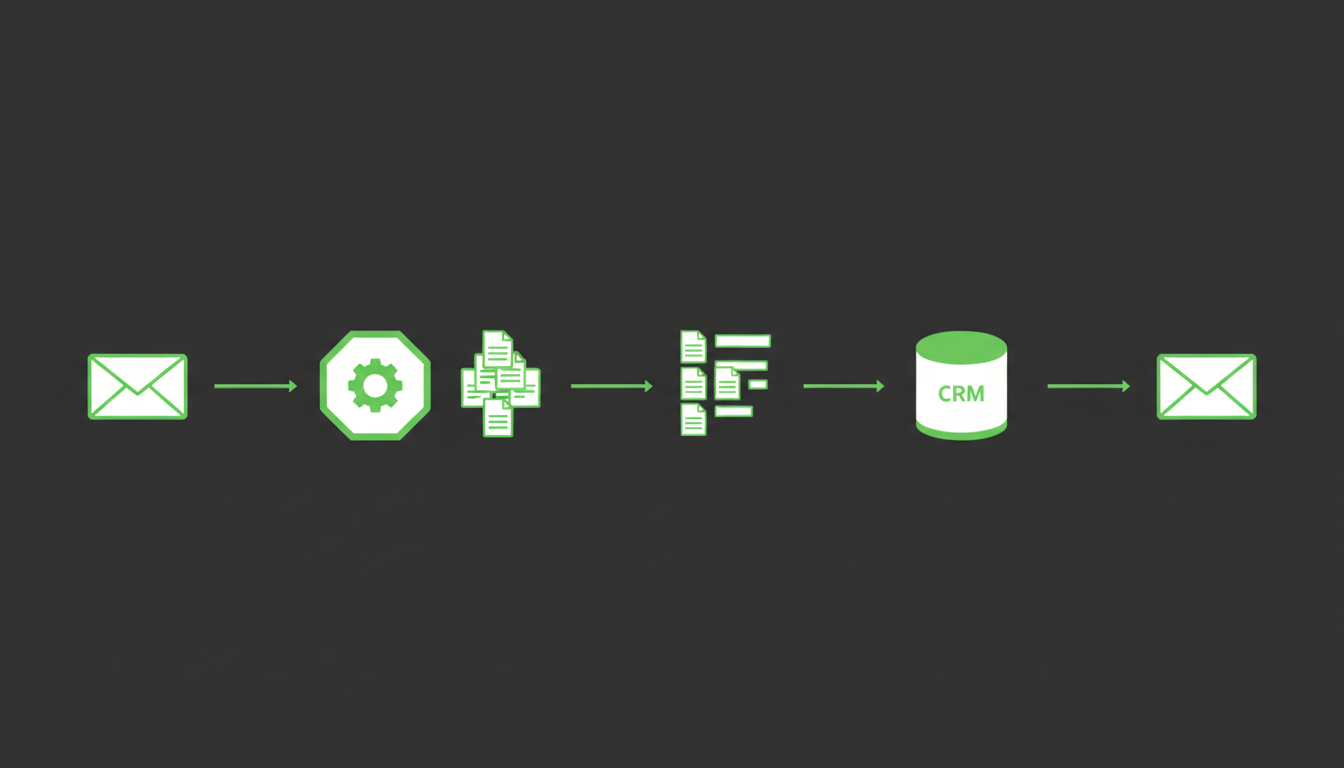
这还只是最标准的一条。遇上同时发合同扫描件、附历史订单截图、要求对比两个版本条款的,再往上加两三个模型也正常。
模型链路从 0.5B 到 70B+,既要快,又要省,还要稳。一卡一模型地部署,不可能完成业务需求。
第一个坑:小模型其实最难摆
很多人第一反应是:小模型好办啊,几个 GB 显存就能跑。
它难就难在它小。
那个 0.5B 的入口安全模型,每条请求都要过一次,QPS 高、延迟要压在几十毫秒——因为它卡在整条链路最前面,它慢一毫秒,全链路就慢一毫秒。
这样一个模型,你让它独占一张 80GB 的 A100?显存用了 3 个 GB,算力只用 5%,剩下全在那儿空转。你让它跟别的模型挤一张卡又不做隔离?它的延迟会被旁边那个嵌入模型的批处理直接拉爆。
小模型要的是随叫随到,又要互不打扰。 没有细粒度虚拟化的世界里,这件事只能靠多开几张卡硬撑,贵得离谱。

第二个坑:大模型八成时间在空转
换个角度,大模型应该是最简单的——贵就贵点,给它整台 8 卡机器跑 70B 就是了。
直到我们看了一整天的调用数据:那个 70B 模型,整天真正被调用的比例只有 20% 出头,其他时间是完全闲的。
客户做的是 B 端销售,大多数请求根本不需要深度推理——查个报价、确认个物流、发个跟进邮件,小模型和中型模型就够。但只要有一条复杂的合同对比请求进来,大模型必须就在那儿待命,临时拉起来也来不及。
大模型要的是关键时刻能上,不是整天占着位置不动。
这时候你就会想:它空的那 80% 时间能不能借出去?给附件解析借一点、给回复生成借一点、夜里给微调借一点。没有一层细粒度调度做这事的话,那台 8 卡机器就必须一直留着。财务看账单的时候,脸都绿了。
第三个坑:8 个模型的峰谷几乎没对齐
如果这 8 个模型同一时间一起忙一起闲,倒也好办。现实是它们的峰谷完全错开:
- 入口安全、意图识别:全天跑,白天高一点,基本平稳。
- 附件解析:白天 10 点到 16 点是高峰,晚上几乎没请求。
- 深度推理:工作日下午集中,周末只有平时的三分之一。
- 回复生成:跟总请求量走,白天高、夜里低。
- 微调和批处理:通常放半夜。
每一个都按自己峰值独立配卡,这批 GPU 一天里只有两三个小时真的在干活,其他时间大面积空转。钱就这么烧出去了。
解这个题不是多买卡,是让同一批卡在不同模型之间流动起来。 附件解析高峰时,从半夜才跑的微调那儿借资源;深度推理排队时,把嵌入模型临时让出的空间接过来。
听起来简单,做起来不简单。它要求底座既能细粒度切分、又能按秒感知负载、还要在不同工作负载之间动态调配——这已经不是"切卡"能概括的事情了。
往上一层:网关的聪明,得看池子能不能动
说到这里顺便把 AI 网关带一句。
大家都说智能体系统的 AI 网关要"智能路由"——每条请求判断走哪个模型、哪个实例、要不要降级、能不能灰度。
但网关的智能有个前提:下面的模型池本身得有腾挪空间。每个模型都死死绑在几张固定的卡上,请求一多就只能原地排队,网关再怎么算,最后都会退化成先来先服务。
网关再聪明,底下池子动不了,也白搭。
再往上一层:MaaS 想做成平台,也卡在这件事
再往上是 MaaS(Model as a Service,把模型托管成可按需调用的服务平台)这层。业务一多,模型数量从几个变几十个,不可能一个模型一套运维,必须收敛成一个统一托管、按需扩缩的平台。
这个平台真正想做成的是这件事:新模型一接进来立刻能分到算力;老模型下线资源立刻被回收;不同模型之间能互相让渡。能不能做成,100% 取决于底下 GPU 池是不是细粒度的、可流动的。如果还是整卡分配,MaaS 层就退化成一个带 UI 的模型仓库,跟运营没啥关系。
所以 GPU 虚拟化在解什么题
把话收一下。
智能体系统里 GPU 虚拟化解的题,说穿了就一件事:让一批参数差异极大、峰谷完全错开的模型,在同一批卡上同时活下来,还能跟着请求实时流动。
能不能跑起来,不看上面那个大模型有多聪明,看下面这层 GPU 池有没有被组织对。
什么时候不必折腾这套
不是所有场景都值得往这个方向走:
- 只跑一个模型、流量稳定、一两张卡够用——整卡部署简单好维护,别折腾。
- 业务还在 POC 阶段、模型都没定——先把业务跑顺再说。
- 没有算力平台团队,也没打算建——虚拟化和调度需要人长期运营,没人管就是新的技术债。
- 业务主要是大规模分布式训练——那是另一个话题,细粒度共享收益有限。
一个实在的判断标准:每加一个新模型就要开一次采购流程,或者峰值撑不住、低谷又一堆卡闲着——就是必须认真做这层的时候。
回到那 4 张 A100
文章开头那个客户,后来把这 8 个模型在同一批 A100 上跑了下来,还留出了夜里跑微调的时间窗。真正改的不是模型,是底下那层资源怎么被组织。
智能体时代 GPU 虚拟化在解什么题?让那条跨 0.5B 到 70B 的模型链路,能在同一批卡上稳定运行——就这一件事。
参考链接
https://gpu.tf https://github.com/NexusGPU/tensor-fusion https://www.anthropic.com/research/building-effective-agents https://vllm.ai/blog/vllm https://developer.nvidia.com/blog/deploying-disaggregated-llm-inference-workloads-on-kubernetes/